
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
机器学习与传统统计在心血管疾病特异性死亡率预测中的较量:非侵入性指标的突破性价值
【字体: 大 中 小 】 时间:2025年10月09日 来源:Scientific Reports 3.9
编辑推荐:
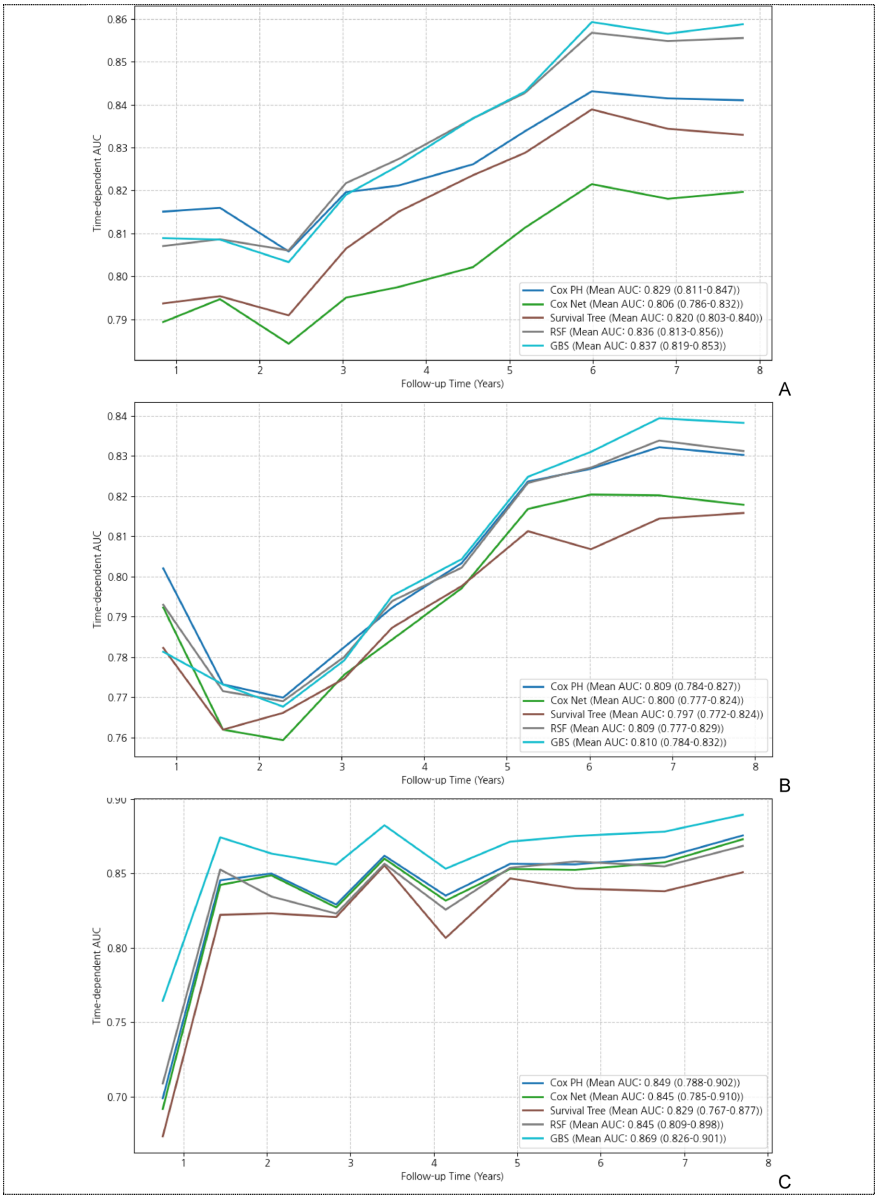
本研究针对心血管疾病(CVD)特异性死亡率预测模型在亚洲人群中的适用性问题,利用韩国大规模队列数据,系统比较了传统统计方法与机器学习模型在仅使用非侵入性指标及联合侵入性指标时的预测效能。研究发现,仅基于年龄、性别、腰高比(WHtR)、糖尿病、高血压和体力活动等非侵入性变量的模型(AUC>0.800)不劣于加入血脂谱的模型,且机器学习方法(如RSF和GBS)展现出略优的时序判别能力。该研究为开发适用于亚洲人群的简易高效CVD风险评估工具提供了重要依据,对临床决策和公共卫生策略具有指导意义。
 生物通微信公众号
生物通微信公众号
知名企业招聘

