
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于多模型对比的甲状腺乳头状癌淋巴结转移风险术前预测:提升临床决策精准性的新策略
【字体: 大 中 小 】 时间:2025年10月10日 来源:Scientific Reports 3.9
编辑推荐:
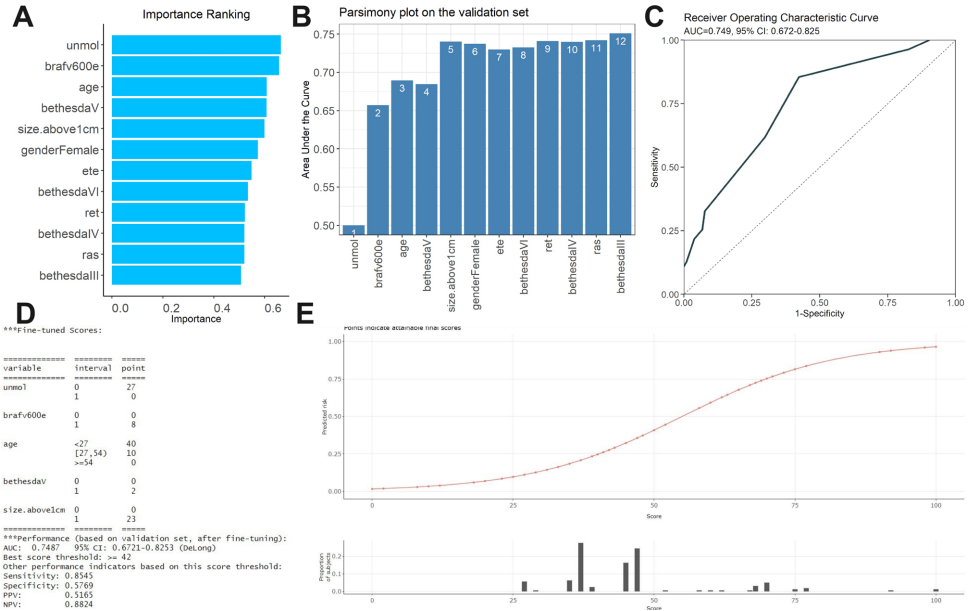
本研究针对甲状腺乳头状癌(PTC)手术中淋巴结清扫范围的临床争议,通过系统比较四种逻辑回归(LR)模型与四种机器学习(ML)算法,构建了术前预测淋巴结转移(LNM)风险的优化模型。研究发现基于最佳子集回归(BestSubset)筛选的LR模型(BestSubset_GLM)在内部验证(AUC=0.770)和中外人群外部验证(中国队列AUC=0.831;加拿大队列AUC=0.785)中均表现出优异泛化能力,其高特异性(0.86)和精准校准特性(Brier Score<0.20)可为临床提供可靠决策支持。该模型通过动态列线图实现可视化应用,有效平衡模型简约性与预测准确性,为个体化手术方案制定提供了重要工具。



 生物通微信公众号
生物通微信公众号
知名企业招聘

