
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
L1图片命名规范对L2图片命名表现的有限预测价值:希伯来语L1与L2说话者的对比研究
【字体: 大 中 小 】 时间:2025年10月19日 来源:Applied Psycholinguistics 2.8
编辑推荐:
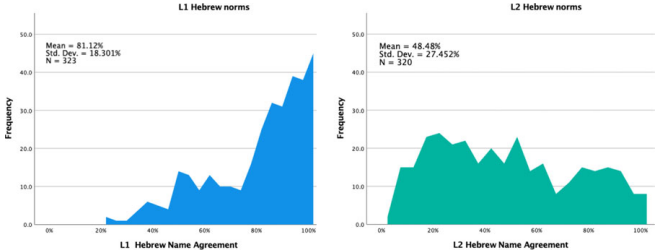
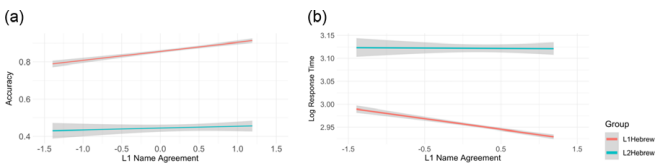
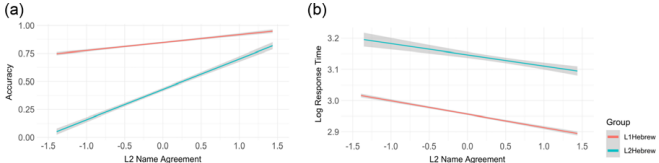
语 本研究针对双语研究中常直接采用L1(第一语言)图片命名规范预测L2(第二语言)说话者命名表现的问题,通过收集希伯来语L1和L2(母语为阿拉伯语)者对320张彩色真实图片的命名规范(名称一致性、熟悉度、典型性等),并对比其与限时图片命名任务中反应时(RT)和准确率的关联。结果发现,L1规范能有效预测L1说话者的命名表现,但对L2说话者预测力有限;而L2衍生的规范显著预测L2表现。此研究强调在多语言研究中需针对不同语言群体制定特异性规范,为双语产出研究提供重要方法学启示。
 生物通微信公众号
生物通微信公众号
知名企业招聘

