
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于Swin Transformer的构音障碍语音识别新框架:DSR-Swinoid模型的创新与突破
【字体: 大 中 小 】 时间:2025年06月17日 来源:Scientific Reports 3.8
编辑推荐:
本研究针对构音障碍(Dysarthria)患者语音识别准确率低的问题,提出了一种基于Swin Transformer(ST)的新型识别框架DSR-Swinoid。通过引入局部特征捕获网络(NLF)、卷积块拼接(CPC)、多路径(MP)和多视角模块(MVB),显著提升了模型对局部特征的提取能力。实验结果表明,该模型识别准确率达98.66%,优于现有方法,为神经系统疾病患者的语音康复提供了AI技术支持。
构音障碍是中风、帕金森病和脑瘫等神经系统疾病的常见并发症,严重影响患者的沟通能力。传统诊断方法依赖医生主观评估,耗时耗力且成本高昂。虽然机器学习方法如支持向量机(SVM)和高斯混合模型-隐马尔可夫模型(GMM-HMM)已被应用于语音识别,但仍面临误报率高、环境噪声干扰等问题。更棘手的是,构音障碍语音的模糊音素信息和数据稀缺性进一步增加了识别难度。
为解决这些挑战,巴基斯坦Taxila工程技术大学计算机科学系的Rabbia Mahum联合沙特阿拉伯国王大学等机构的研究团队,在《Scientific Reports》发表了一项创新研究。该团队开发了基于Swin Transformer的DSR-Swinoid模型,通过四个关键技术创新――局部特征提取网络(NLF)、卷积块拼接(CPC)、多路径(MP)融合和多视角模块(MVB),成功将构音障碍语音识别准确率提升至98.66%。
研究采用Mel频谱图转换技术将语音信号转化为视觉表示,克服了传统声学模型对音素信息的依赖。关键技术包括:1)使用公开的Nemours构音障碍语音数据库和ASVSpoof 2019健康语音数据集;2)采用Sigmoid激活函数替代传统ReLU,增强模型稳定性;3)引入Inception多头自注意力机制(IMSA)整合不同感受野特征;4)通过梯度加权类激活映射(Grad-CAM)可视化模型决策过程。
【网络结构设计】
研究团队在Swin Transformer基础上创新性地加入NLF模块,通过三层卷积结构(3×3核)提取低层局部特征,相比传统4×4非重叠分块方式更有效保留细节信息。CPC模块采用步长为2的3×3卷积层,在保持层级特征的同时增强局部特征捕获能力。
【多阶段特征融合】
MP模块创新性地融合阶段2(Istage2
)和阶段4(Istage4
)特征,通过公式Ifinal
=Concat(Istage2
,Istage4
)实现局部与全局特征的互补。消融实验证明,这种组合使识别准确率提升31.02%,显著优于单阶段特征。
【多视角注意力机制】
MVB模块将输入窗口分为三个通道(Iw1
, Iw2
, Iw3
),分别应用1×1、3×3和5×5卷积核,通过公式Jc
=Concat(Jw1
,Jw2
,Jw3
)整合多尺度特征。这种设计使模型能同时捕捉细微发音异常和整体语音模式。
【跨数据集验证】
在TORGO数据库测试中,模型对不同严重程度构音障碍(中度准确率98.13%-99.22%,轻度98.87%-99.12%)均保持稳定性能。可视化分析显示,DSR-Swinoid能精准定位Mel频谱图中的异常区域,如图5所示:
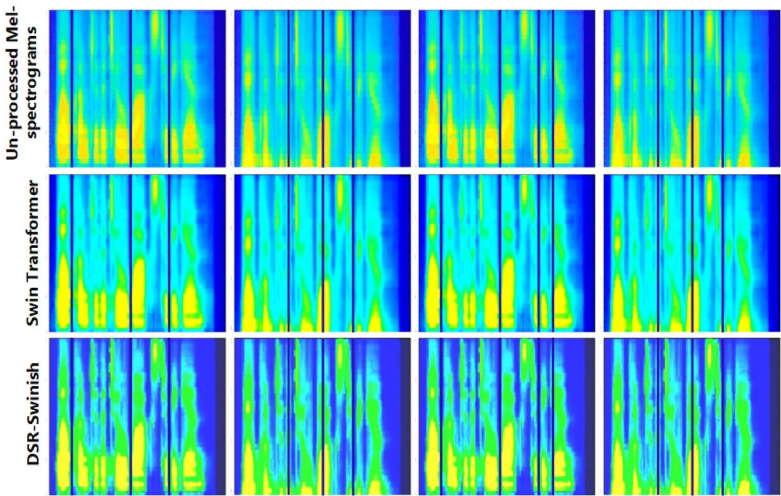
研究结论表明,DSR-Swinoid通过局部-全局特征协同提取机制,有效解决了构音障碍语音识别中的三大核心挑战:音素模糊性、数据稀缺性和环境敏感性。相比现有最佳模型(CNN-GRU的98.38%准确率),该框架将识别性能提升0.28个百分点,同时计算耗时仅1.2毫秒。
这项研究的临床意义在于:1)为早期发现神经系统疾病恶化提供客观指标;2)支持个性化康复方案制定;3)通过实时反馈提升患者语言训练效果。团队已与巴基斯坦P.O.F医院合作,将系统用于中风前期的言语障碍筛查。未来工作将探索模型在移动端的轻量化部署,并扩展至更多语言场景的应用。
生物通微信公众号
知名企业招聘

