
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
大型语言模型在牙科教育评估中的表现与潜力:GPT-4o、Grok2和Gemini的对比研究
【字体: 大 中 小 】 时间:2025年06月22日 来源:British Dental Journal 2.0
编辑推荐:
本研究针对人工智能在牙科教育中的应用瓶颈,系统评估了GPT-4o、Grok2和Gemini三种大型语言模型(LLMs)在英国牙科手术学士(BDS)和口腔卫生治疗(DHT)评估中的表现。研究发现LLMs能通过所有年级的笔试评估,其中Grok2在BDS简答题中表现最优,而DHT评估中GPT-4o与Grok2显著优于Gemini。尽管LLMs可生成考题,但存在题干表述和评分标准不一致等问题,为AI辅助牙科教育提供了重要实证依据。
在人工智能席卷医疗教育领域的浪潮中,牙科教育正面临前所未有的机遇与挑战。传统牙科评估体系依赖人工命题和阅卷,存在效率低下、标准化程度不足等问题。与此同时,以ChatGPT为代表的大型语言模型(LLMs)已展现出在医学考试中媲美人类考生的潜力,但其在专科性极强的牙科教育中的表现仍缺乏系统评估。英国曼彻斯特大学领衔的研究团队在《British Dental Journal》发表的重要研究,首次对主流LLMs进行了全面的牙科教育评估能力"大比武"。
研究团队设计了一套严谨的评估体系:从英国牙科学院题库中选取340道多选题(MCQs)、80道简答题(SAPs)和3场结构化口试,覆盖牙科手术学士(BDS)1-5年级和口腔卫生治疗(DHT)1-3年级全部课程。三大主流模型GPT-4o、Grok2和Gemini同台竞技,不仅接受"考生"身份的测试,还尝试扮演"考官"角色生成140道评估题目。所有结果均由资深牙科教育专家团队采用双盲评估。
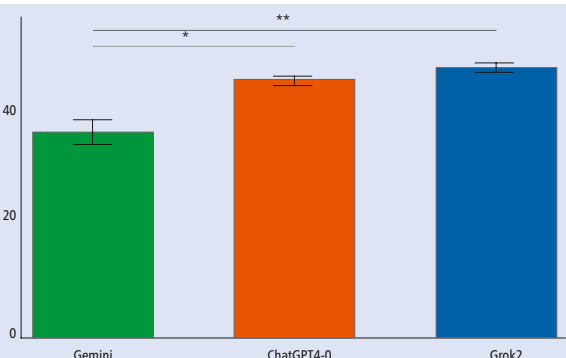
在MCQs测试中,三大模型展现出惊人一致性。BDS课程中GPT-4o在低年级稍占优势,但随着题目难度增加,Grok2表现稳步提升。值得注意的是,所有模型在所有年级的MCQs测试中均达到及格线,印证了LLMs具备基础牙科知识储备。DHT课程的MCQs测试同样未出现显著差异,表明LLMs对口腔卫生治疗知识的掌握程度相当。
SAPs评估则揭示了模型的差异化表现。BDS课程中Grok2以微弱优势领跑,特别是在高年级临床应用题中展现出更强的问题解析能力。DHT评估则出现明显分层:GPT-4o和Grok2组成"第一梯队",显著优于Gemini。研究特别指出,在涉及临床决策的题目中,Grok2表现出更符合临床指南的思维路径。
当角色转换为"考官"时,LLMs的表现喜忧参半。MCQs生成方面,模型能构建符合认知层次的知识点考查,但在干扰项设计上常出现专业瑕疵。例如在儿童牙科题目中,可能同时设置两个临床正确的选项,违背了"单一最佳答案"原则。SAPs的评分标准制定成为最大短板,约30%的生成题目因评分细则过于冗长或模糊被判定不合格。
结构化口试的模拟彻底暴露了LLMs的局限。虽然能生成合理的病例场景,但后续追问问题和评分标准往往脱离临床实际。研究记录了一个典型失误:在儿科病例中,模型生成的"处理方案评分标准"竟包含已被淘汰的治疗方法。
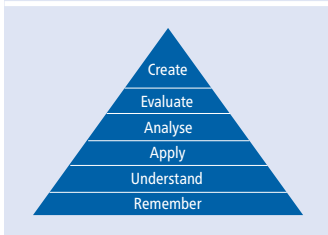
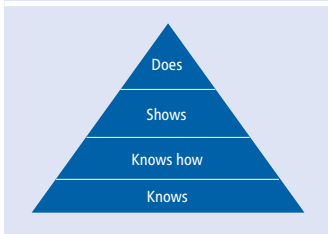
从教育测量学角度分析,LLMs生成的题目多集中在Bloom分类法的"记忆"和"理解"层面,仅少数临床题目能达到"应用"层次。在Miller金字塔的评估中,MCQs主要测试"知道(knows)"层面知识,而优秀的SAPs题目可触及"知道如何做(knows how)"层面,这正是临床能力培养的关键。
该研究的创新价值在于首次系统评估了LLMs在牙科教育的双向应用潜力。结论指出:GPT-4o和Grok2已具备辅助牙科教学的能力,特别是在形成性评估和个性化学习支持方面优势明显。但LLMs暂不能替代专业教师在终结性评估中的核心作用,尤其在需要高阶临床思维的评价环节。
这项研究为牙科教育数字化转型提供了重要路标。随着模型迭代,LLMs有望缓解牙科教育中师资不足的困境,但需要建立"人机协作"的质量控制体系。研究者特别强调,教育者需掌握"提示工程(prompt engineering)"技巧,通过提供课程目标、评分标准等关键参数,显著提升LLMs的输出质量。未来研究可探索多模态LLMs在牙科OSCE考核中的应用,这将进一步拓展AI在教育评估中的疆域。
生物通微信公众号
知名企业招聘

