
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于多蛋白语言模型嵌入的StackGlyEmbed算法:N-连接糖基化位点预测新突破
【字体: 大 中 小 】 时间:2025年06月29日 来源:Bioinformatics Advances 2.4
编辑推荐:
本研究针对N-连接糖基化位点实验检测成本高、现有预测方法性能不足的问题,开发了集成ProtT5-XL-U50、ESM-2和ProteinBERT多模型嵌入特征的StackGlyEmbed算法。该模型通过堆叠SVM/XGB/KNN基学习器和SVM元学习器,在独立测试中实现98.2%灵敏度、92.5%平衡准确率和82.6%MCC值,显著超越现有方法,为糖蛋白功能研究提供了高效计算工具。
在生命活动中,蛋白质的N-连接糖基化(N-linked glycosylation)是一种关键的翻译后修饰(PTM),它通过寡糖链与天冬酰胺(Asn/N)共价结合,参与蛋白质折叠、免疫应答和细胞通讯等重要过程。这种修饰通常发生在高度保守的N-X-S/T序列(X≠脯氨酸)中,但令人困扰的是,含有该序列的位点并非都会被糖基化。传统质谱检测方法虽然准确,但耗时耗力且成本高昂,而现有计算方法要么依赖人工设计特征导致偏差,要么未能充分利用序列上下文信息。
针对这一挑战,孟加拉国工程技术大学(BUET)和联合国际大学(UIU)的研究团队在《Bioinformatics Advances》发表了创新性成果。研究者开发了名为StackGlyEmbed的堆叠集成模型,首次整合ProtT5-XL-U50、ESM-2和ProteinBERT三种蛋白语言模型(PLM)的嵌入特征,通过系统特征选择和模型优化,在N-GlyDE和N-GlycositeAtlas数据集上实现了超越现有方法的预测性能。
研究采用的关键技术包括:1)从UniProt获取的人类糖蛋白数据集构建与CD-HIT去冗余;2)ProtT5-XL-U50(1024维)、ESM-2(1280维)和ProteinBERT(512维)的序列嵌入特征提取;3)增量特征选择(IFS)确定最优特征组合;4)基于互信息的SVM/XGB/KNN基学习器选择与SVM元学习器构建;5)SHAP值分析解释模型决策机制。
特征选择与模型构建
通过增量特征选择(IFS)确定ProteinBERT全局嵌入、ESM-2窗口(31残基)平均嵌入和ProtT5-XL-U50单残基嵌入的最优组合(FC-1)。当加入基学习器概率(BLP)形成FC-2特征集时,SHAP分析显示BLP贡献度最高(图6),证实了堆叠架构的有效性。

性能比较
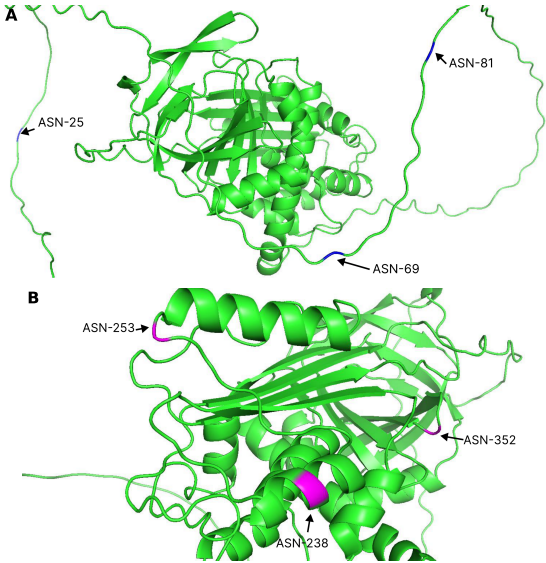
在N-GlyDE独立测试集上,StackGlyEmbed以98.2%灵敏度(SN)、92.5%平衡准确率(BACC)和82.6%马修斯相关系数(MCC)全面超越LMNglyPred(74.7% SN)和DeepNGlyPred(72.5% SN)。特别在柔性区域糖基化位点预测中(如UniProt P05155蛋白的25、69、81位点),该模型展现出独特优势(图8),而其他方法仅能识别刚性结构域位点。
讨论与展望
该研究首次证明:1)融合多PLM嵌入能更全面捕捉糖基化序列特征;2)传统机器学习堆叠架构在中等规模数据集上优于深度学习;3)窗口特征(如ESM-2-Window)能有效捕获局部环境信息。虽然模型在跨数据集测试中表现受限(反映N-GlyDE与N-GlycositeAtlas的数据异质性),但合并数据集训练后性能显著提升,提示未来可通过迁移学习解决领域适应问题。
这项工作的现实意义在于:1)为缺乏三维结构数据的糖蛋白研究提供纯序列解决方案;2)开源工具(GitHub可获取)将加速糖生物学发现;3)建立的特征工程框架可拓展至其他PTM预测。正如研究者强调,该方法仅需序列信息即可实现高性能预测,使其在大规模组学研究中具有独特应用价值,为理解糖基化在疾病发生、疫苗设计等领域的分子机制提供了新工具。
生物通微信公众号
知名企业招聘

