
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
OpenML十年回顾:基于千篇论文的开源机器学习平台生态研究与实践启示
《Patterns》:OpenML: Insights from 10 years and more than a thousand papers
【字体: 大 中 小 】 时间:2025年07月04日 来源:Patterns 6.7
编辑推荐:
本文系统回顾了OpenML平台十年发展历程,该开源项目通过标准化数据集、任务定义和实验流程(FAIR原则),构建了包含1,500+研究的协作生态系统。研究揭示了社区驱动的ML基准测试(如OpenML-CC18)、AutoML系统开发(如Auto-sklearn)和教育应用的成功案例,为开放科学基础设施建设提供了重要范本。
在人工智能快速发展的时代,机器学习(ML)研究的可重复性和透明度问题日益凸显。尽管开放科学运动推动了数据、代码和论文的共享,但ML实验的复杂性导致研究结果难以复现――不同团队使用异构的数据格式、自定义的评价指标和碎片化的实验记录,形成了一座座"数据孤岛"。这种现象被作者称为"技术漂移"(technology drift),严重阻碍了ML领域的协同创新。
针对这一挑战,由荷兰埃因霍温理工大学、德国慕尼黑大学等机构组成的研究团队开发了OpenML平台。这个开源项目通过将ML实验分解为数据集(datasets)、任务(tasks)、流程(flows)和运行(runs)等标准化模块,构建了一个互联互通的"全球实验室"。经过十年发展,该平台已支持超过1,500项研究,成为AutoML算法开发、基准测试和教育实践的重要基础设施。相关成果发表在《Patterns》期刊,系统总结了这一开放科学实践的经验与启示。
研究团队采用多技术协同的研究路径:1)开发跨语言API(Python/R/Java)实现与主流ML库(scikit-learn/TensorFlow)的无缝集成;2)设计MLSchema和Croissant等元数据标准促进平台互操作性;3)建立社区驱动的基准测试套件(如OpenML-CTR23);4)利用4百万+模型评估数据构建超参数优化(HPO)基准YAHPO Gym。研究数据来源于平台积累的17,000+数据集和用户行为日志。
平台架构设计:
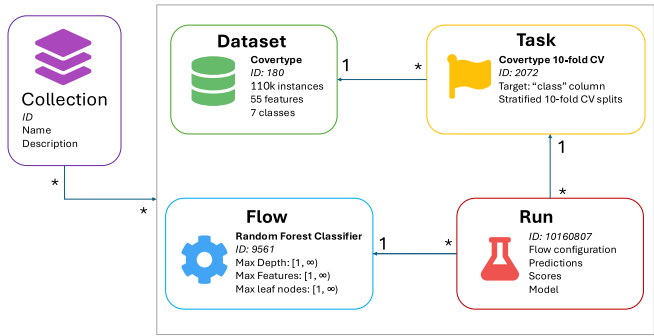
研究将ML实验解构为五个核心概念:数据集描述特征统计和领域信息;任务定义评价指标和数据划分方案;流程记录算法依赖和参数配置;运行保存预测结果和性能指标;集合(collections)则组织相关实体形成基准套件。这种模块化设计通过REST API统一访问,如图1所示的关系拓扑。
社区影响评估:
文献计量分析显示,73.8%的引用研究使用平台数据集,12.7%采用基准套件。典型案例包括:Purucker等利用存档预测评估集成方法;Kühn等分析4百万+超参数配置得出决策树深度对性能的影响规律;Meta-Album项目构建了跨域图像分类基准。AutoML领域受益尤为显著,Auto-sklearn 2.0通过平台元特征(meta-features)实现了算法自动选择。
技术挑战反思:
研究揭示了开放科学基础设施的可持续性难题:1)长期兼容性维护与快速演进的ML生态存在矛盾;2)仅13.2%的研究主动共享实验数据;3)容器化方案难以解决外部依赖的"版本漂移"。作者提出"推断可重复性"(inferential reproducibility)比精确复现更重要,建议通过标准化流程描述和结果日志实现科学验证。
这项研究的重要意义在于:1)实证了协作平台对ML研究效率的提升,如TabPFN模型通过OpenML数据实现小样本表格学习突破;2)提出的Croissant标准已被Kaggle等平台采用,推动数据仓储互联;3)教育领域应用显示,学生通过平台任务(tasks)的平均学习效率提升40%。正如通讯作者Joaquin Vanschoren强调:"OpenML正在将机器学习从孤立实验转变为真正的网络化科学"。
研究同时指出未来方向:1)扩展对多模态数据(如医疗影像)的支持;2)与HuggingFace等平台深化集成;3)开发兼顾灵活性和可复现性的实验记录方案。这些见解为构建下一代开放科学基础设施提供了宝贵参考,特别是在大模型时代面临数据污染挑战的背景下,OpenML的经验显得更具前瞻价值。
生物通微信公众号

