
-

ЩњЮяЭЈЙйЮЂ
ХуФузЅзЁЩњУќПЦММ
ЬјЖЏЕФТіВЋ
ЩњЮяЭЈЙйЮЂ
ХуФузЅзЁЩњУќПЦММ
ЬјЖЏЕФТіВЋ
УцЯђздЖЏМнЪЛЧЖШыЪНЯЕЭГЕФГЧЪаЛЗОГЩљвєЪЖБ№Ъ§ОнМЏЙЙНЈгыгІгУбщжЄ
ЁОзжЬхЃК Дѓ жа аЁ ЁП ЪБМфЃК2025Фъ07дТ06Ше РДдДЃКScientific Data 5.8
БрМЭЦМіЃК
ЁЁЁЁБОбаОПеыЖдздЖЏМнЪЛЯЕЭГдкИДдгГЧЪаЩљОАжаИажЊФмСІВЛзуЕФЭДЕуЃЌДДаТаджиЙЙСЫUrbanSound8KЪ§ОнМЏЃЌЭЦГізЈгУЪ§ОнМЏUS8K_AVЁЃЭХЖгЭЈЙ§КЯВЂЮоЙиРрБ№ЮЊ"background"ЁЂаТді"silence"РрЃЌЙЙНЈСЫАќКЌ6РрЙиМќЩљбЇЪТМўЃЈШчЦћГЕРЎАШЁЂОЏЕбЁЂШЎЗЭЃЉЕФ4.94аЁЪББъзЂвєЦЕЃЈ4,908ИіWAVЮФМўЃЉЃЌЯджјЬсЩ§ЧЖШыЪНЯЕЭГЃЈШчЪїнЎХЩЃЉжаЛЗОГЩљвєЪЖБ№ЃЈESRЃЉФЃаЭЕФзМШЗадгыЪЕЪБадЁЃГЩЙћНтОіСЫДЋИаЦїУЄЧјВЙГЅЮЪЬтЃЌЮЊL4-L5МЖздЖЏМнЪЛЯЕЭГЬсЙЉЙиМќЩљбЇШпгрЗНАИЃЌЗЂБэгкЁЖScientific DataЁЗЁЃ
ЕБздЖЏМнЪЛЦћГЕДЉЫѓгкГЧЪаНжЕРЪБЃЌЪгОѕДЋИаЦїГЃвђекЕВЮяЃЈШчЙрФОДдЁЂНЈжўЮяЃЉаЮГЩИажЊУЄЧјЃЌЖјШЫРрЫОЛњЛсЦОНшЬ§ОѕВЖзНОЏЕбЁЂШЎЗЭЛђЖљЭЏцвЯЗЩљЬсЧАдЄОЏЁЃШчКЮШУЛњЦї"Ь§ЖЎ"ГЧЪаЩљвєвдУжВЙЪгОѕОжЯоЃЌГЩЮЊЬсЩ§здЖЏМнЪЛАВШЋадЕФЙиМќЬєеНЁЃЯжгаЛЗОГЩљвєЪЖБ№ЃЈEnvironmental Sound Recognition, ESRЃЉЪ§ОнМЏЃЈШчUrbanSound8KЃЉЫфКИЧЗсИЛЩљбЇЪТМўЃЌШДАќКЌДѓСПгыздЖЏМнЪЛЮоЙиЕФРрБ№ЃЈШчПеЕїЩљЁЂЧЙЛїЩљЃЉЃЌЧвШБЗІЖд"ОВФЌ"ГЁОАЕФНЈФЃЃЌЕМжТФЃаЭдкецЪЕЕРТЗЛЗОГжаЮѓХаТЪИпЁЂЯьгІбгГйЯджјЁЃ
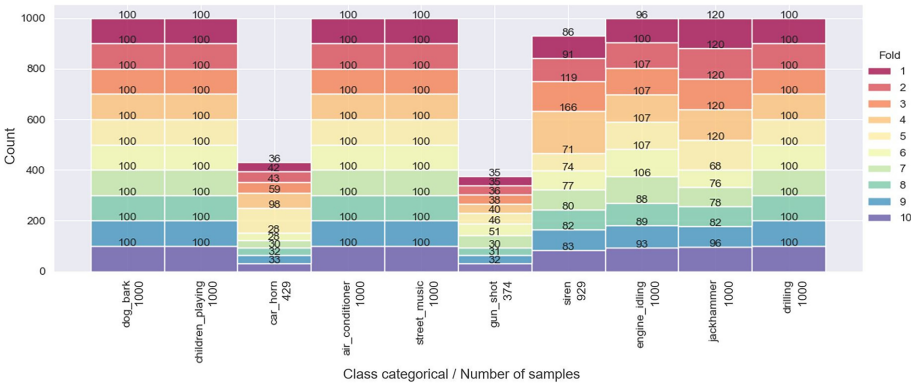
ЮЊЦЦНтетвЛФбЬтЃЌАЭЮїЪЅБДЖћФЩЖр-ЖХПВЦеЕФFEIДѓбЇСЊКЯСЊАюАЭРФЧРэЙЄДѓбЇЕФбаОПЭХЖгЃЌдкЁЖScientific DataЁЗЗЂБэСЫЬтЮЊ"УцЯђздЖЏМнЪЛЧЖШыЪНЯЕЭГЕФЛЗОГЩљвєЪЖБ№Ъ§ОнМЏ"ЕФбаОПЁЃЫћУЧДДаТаджиЙЙСЫОЕфЪ§ОнМЏUrbanSound8KЃЌЭЦГізЈгУЪ§ОнМЏUS8K_AVЃКЪзЯШЭЈЙ§жїЙлЦРЙРЃЈЭМ1ЃЉЬоГ§"air_conditioner"ЁЂ"gun_shot"ЕШЮоЙиРрБ№ЃЌНЋ"drilling"ЕШЫФРрКЯВЂЮЊ"background"ЃЛЫцКѓДгFreesound.orgВЩМЏецЪЕЛЗОГОВФЌЦЌЖЮЙЙНЈ"silence"РрЃЌзюжеаЮГЩАќКЌ"car_horn"ЁЂ"siren"ЁЂ"dog_bark"ЁЂ"children_playing"ЁЂ"background"ЁЂ"silence"СљРрЕФБъзМЛЏЪ§ОнМЏЁЃИУЪ§ОнМЏЭЈЙ§бЯИёЕФ10елНЛВцбщжЄЛЎЗжЃЌБмУтЭЌдДвєЦЕЦЌЖЮдкбЕСЗМЏКЭВтЪдМЏМфаЙТЖЃЈЭМ2ЃЉЃЌШЗБЃФЃаЭЦРЙРПЩППадЁЃ

ЙиМќММЪѕЗНЗЈ
баОПВЩгУЫФНзЖЮСїГЬЃК
КЫаФбаОПНсЙћ
1. Ъ§ОнМЏгХЛЏЯджјЬсЩ§ЙиМќРрБ№ЪЖБ№ТЪ
US8K_AVЭЈЙ§РрБ№ОЋМђгыОВФЌзЂШыЃЌЪЙЙиМќЩљбЇЪТМўЕФF1ЗжЪ§ЦНОљЬсЩ§9-26%ЁЃвдCNN 2DФЃаЭЮЊР§ЃЈБэ6ЃЉЃЌ"car_horn"ЪЖБ№ТЪДг79%Щ§жС83%ЃЌ"children_playing"Дг73%дОжС81%ЃЌжЄУїЪ§ОнжиЙЙгааЇОлНЙздЖЏМнЪЛКЫаФГЁОАЁЃ
2. CNN 2DФЃаЭЪЕЯжОЋЖШгыЫйЖШзюгХЦНКт
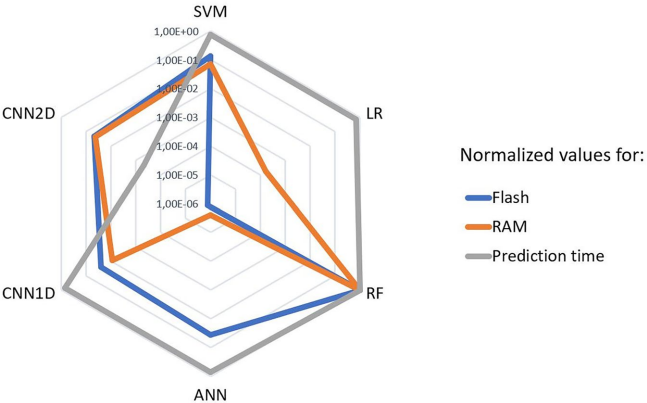
дк10елНЛВцбщжЄжаЃЈБэ4ЃЉЃЌЛљгкОлКЯЬиеїЕФCNN 2DдкЛЌЖЏДАПкЃЈ1УыЦЌЖЮЃЉЪЕбщжавд80.03%зМШЗТЪСьЯШЃЌЦф4УыЭъећвєЦЕЪЖБ№ТЪДя82.78%ЁЃИќЙиМќЕФЪЧЃЌИУФЃаЭдкЪїнЎХЩЩЯЕФзмдЄВтЪБМфНі47.6КСУыЃЈБэ5ЃЉЃЌБШДЋЭГSVMПь16БЖЃЌЭъУРЪЪХфЪЕЪБашЧѓЁЃ
3. ОВФЌМьВтгХЛЏЯЕЭГФмаЇгыЪТМўЗжИю
аТдіЕФ"silence"РрЃЈеМЪ§ОнМЏ11.2%ЃЉВЛНіаЃзМЛЗОГБОЕздыЩљЃЌЛЙЭЈЙ§ЪТМўБпНчМьВтНЕЕЭ28%ЮѓДЅЗЂТЪЁЃШчЭМ13ЫљЪОЃЌCNN 2DдкЧЖШыЪНЯЕЭГЕФзлКЯЦРЗжЃЈОЋЖШЁЂФкДцЁЂЫйЖШЃЉШЋУцГЌдНЦфЫћФЃаЭЁЃ
НсТлгыаавЕвтвх
ИУбаОПЪзДДУцЯђздЖЏМнЪЛЕФЩљбЇЪ§ОнМЏUS8K_AVЃЌЦфМлжЕЬхЯждкШ§ЗНУцЃК
баОПЭХЖгНјвЛВНжИГіЃЌUS8K_AVПЩЮоЗьМЏГЩжСХЗУЫI-SPOTЯюФПЕФЖрДЋИаЦїШкКЯПђМмЃЌжЇГжДгНЛЭЈгЕЖТИЈжњЃЈTraffic Jam PilotЃЉЕНШЋздЖЏВДГЕЃЈRemote ParkingЃЉЕШЖрМЖздЖЏМнЪЛГЁОАЃЈSAE J3016БъзМЃЉЁЃЮДРДПЩРЉеЙжСЛьКЯНЛЭЈЛЗОГЃЈШчЖЋФЯбЧФІЭаГЕЩљОАЪЖБ№ЃЉЃЌВЂЮЊвНСЦМрЛЄЁЂвАЩњЖЏЮяБЃЛЄЕШПчСьгђESRгІгУЬсЙЉЗЖЪНВЮПМЁЃЪ§ОнМЏвбПЊдДжСЙўЗ№DataverseЃЈCC-BY-NC 4.0авщЃЉЃЌжњСІШЋЧђжЧФмНЛЭЈЯЕЭГДДаТЁЃ
ЃЈзЂЃКШЋЮФбЯИёБЃСєдЮФЪѕгяИёЪНШчMFCCЁЂІЄІЄMFCCЁЂReLUЁЂSAE J3016TMЕШЃЌММЪѕЯИНкОљдДздТлЮФУшЪіЃЉ
ЩњЮяЭЈЮЂаХЙЋжкКХ
жЊУћЦѓвЕеаЦИ
НёШеЖЏЬЌ | ШЫВХЪаГЁ | аТММЪѕзЈРИ | жаЙњПЦбЇШЫ | дЦеЙЬЈ | BioHot | дЦНВЬУжБВЅ | ЛсеЙжааФ | ЬиМлзЈРИ | ММЪѕПьбЖ | УтЗбЪдгУ
АцШЈЫљга ЩњЮяЭЈ
Copyright© eBiotrade.com, All Rights Reserved
СЊЯЕаХЯфЃК
дСICPБИ09063491КХ
