
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
中国县级月度CO2排放数据集(2013-2021):基于多源数据融合与混合回归算法的创新估算
【字体: 大 中 小 】 时间:2025年07月15日 来源:Scientific Data 5.8
编辑推荐:
本研究突破传统夜间灯光数据的单一局限,通过耦合改进校准的NPP/VIIRS夜间灯光数据、城乡人居环境数据及社会经济指标,构建包含37个特征变量的预测体系,创新性地采用DNN-CatBoost混合回归算法生成与CO2排放线性相关性更强的工具变量。团队成功估算了2013-2021年中国2771个县区的月度CO2排放量,其测试集R2达0.99,为"双碳"战略的县级目标分解提供高精度时空数据支撑。
在全球气候变暖加剧的背景下,冰川融化、生态恶化等环境问题日益严峻。作为全球最大CO2排放国,中国"双碳"战略的实施亟需高精度的基层排放数据支撑。然而现有县级排放估算存在明显缺陷:传统自上而下方法仅依赖单一夜间灯光亮度指标,错误假设省内所有区域CO2排放与灯光亮度均呈正相关;而自下而上方法则常遗漏小型排放源,导致数据缺失或低估。更棘手的是,现有研究对NPP/VIIRS夜间灯光数据的连续性校正存在"逐年递增"的偏差,难以反映实际排放波动。
西南财经大学公共管理学院的研究团队在《Scientific Data》发表创新成果,通过构建多源数据融合框架和混合机器学习模型,首次实现了中国县级月度CO2排放的高精度估算。研究整合了七类城乡聚落区的灯光强度、像素数量等23个遥感指标,以及工业结构、绿色专利等14个社会经济变量,采用自编码器特征选择方法筛选出20个关键特征。创新性地结合深度神经网络的特征提取优势与CatBoost算法处理类别变量的能力,构建的预测模型测试集R2达0.99,显著优于传统方法。最终生成的2013-2021年2771个县级月度排放数据集,为差异化减排政策制定提供了科学依据。
关键技术方法包括:1)基于城乡聚落分类的NPP/VIIRS数据精细化校正,避免整体校正导致的"虚假增长";2)通过Pearson相关系数、统计检验等四重特征筛选确定20个核心变量;3)构建DNN-CatBoost混合回归模型,其中DNN模块采用ReLU激活函数进行非线性特征变换,CatBoost模块采用对称树结构处理高维特征;4)采用省级能源消费数据作为基准,通过自上而下算法保证县级汇总数据与宏观统计的一致性。
【背景与方法】研究突破传统单指标局限,将城乡聚落细分为七种类型(如城市中心、半密集城区等),对应提取各类区域的灯光强度、总亮度和像素数量等23个遥感特征,结合14个社会经济指标构成37维特征空间。通过自编码器特征选择发现,农村集群区DN值(X5)、极低密度农村区DN值(X7)等20个变量对排放预测贡献最大。
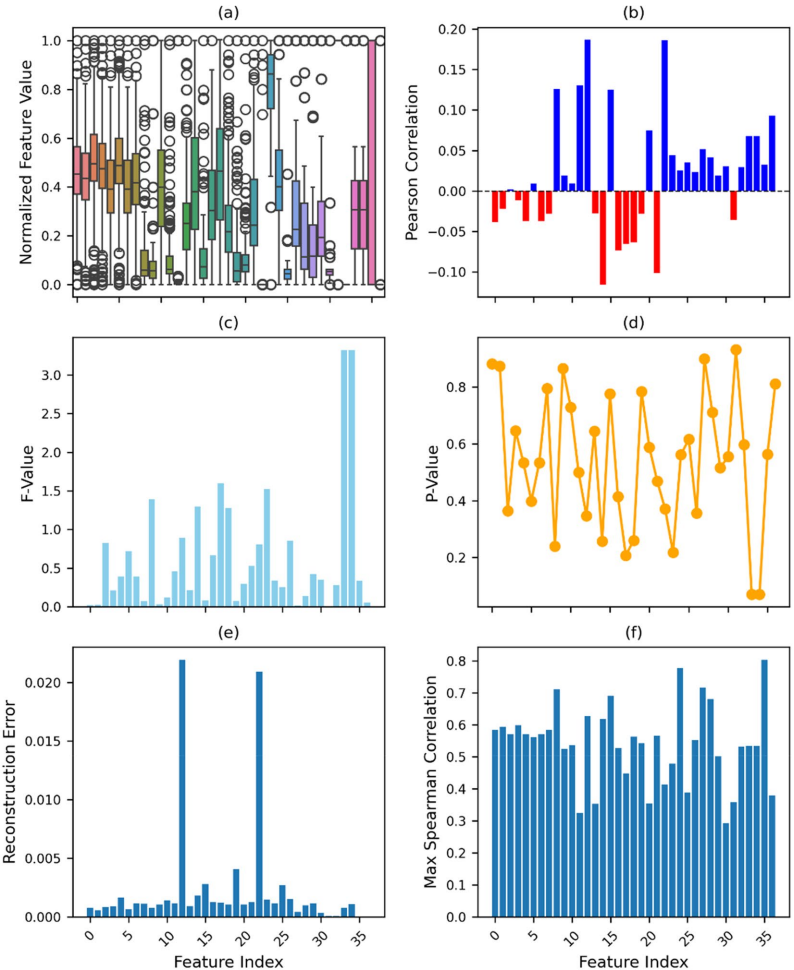
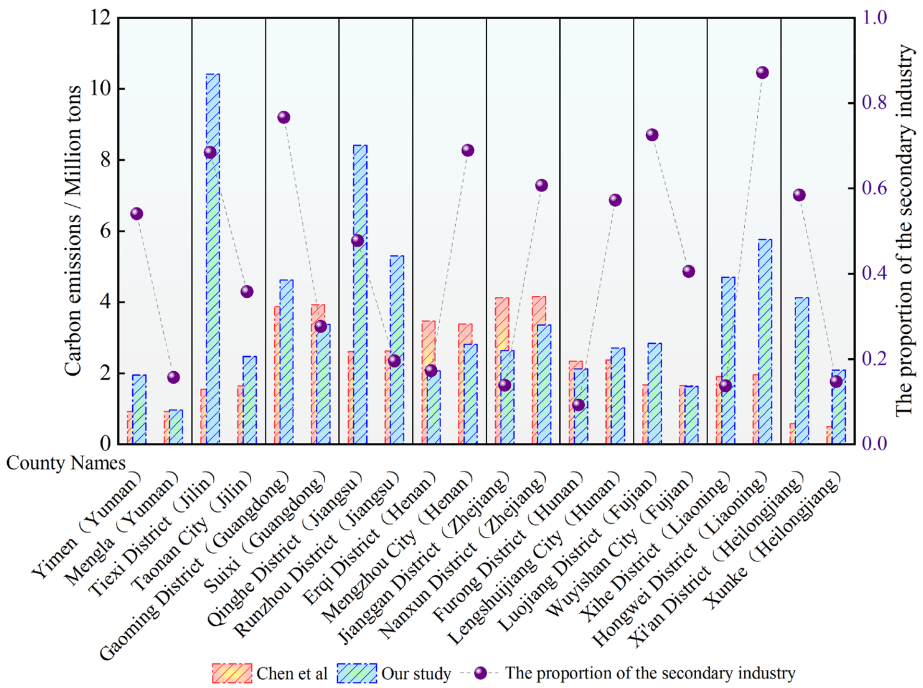
【技术验证】与传统方法相比,新构建的工具变量与GDP的相关系数R2稳定在0.8左右(图5),且测试集RMSE(0.06)显著低于Chen等报道的0.13。典型案例显示,相同省份内工业结构差异显著的县区,在新数据集中被正确区分,而传统方法则产生系统性偏差(图6)。
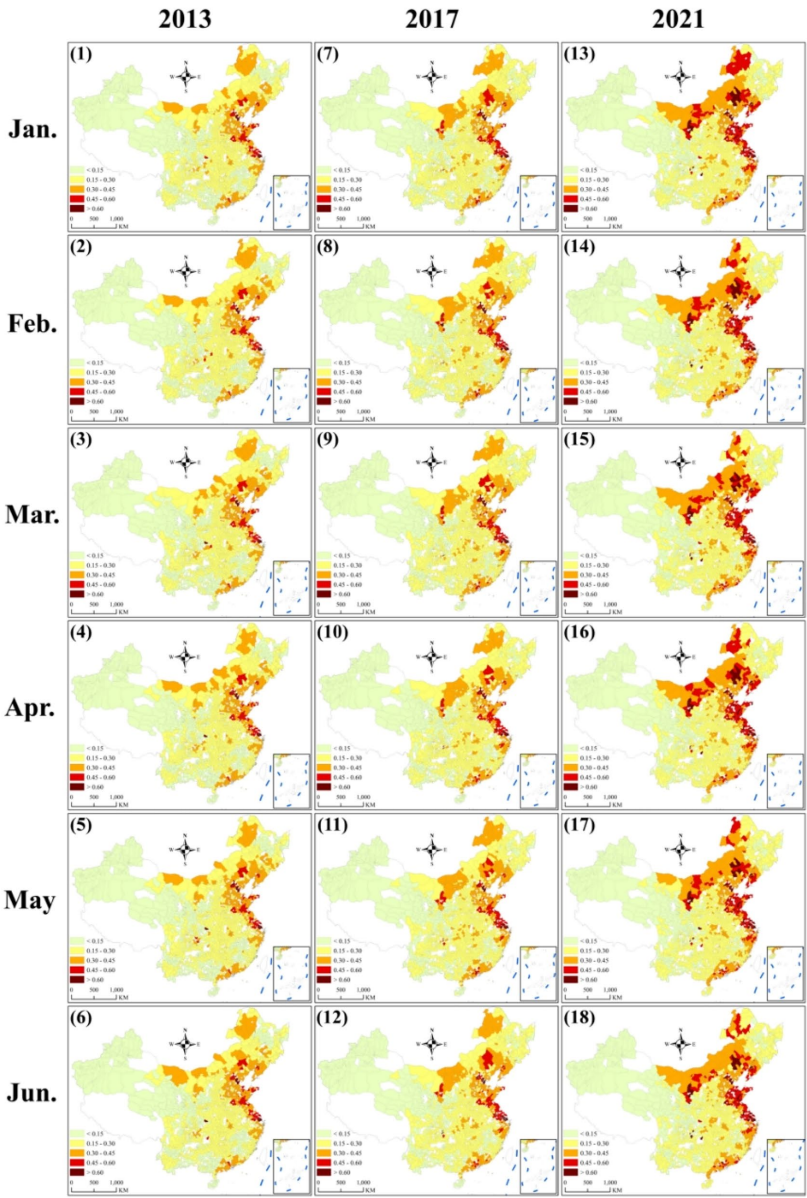
【时空特征】2013-2021年县级排放时空演变显示(图3-4),高排放区主要分布在东部沿海城市群,且呈现明显的季节波动特征。通过分城乡类型的连续性校正,成功捕捉到部分区域排放下降趋势,这是传统"逐年递增"校正方法无法实现的。
该研究通过多源数据融合和算法创新,解决了县级排放估算中的三个关键难题:1)突破单一灯光指标的局限性,首次整合城乡聚落特征与社会经济变量;2)开发基于DNN-CatBoost的混合回归框架,有效处理高维特征并提升小样本训练稳定性;3)建立分城乡类型的灯光数据校正方法,避免传统整体校正导致的系统性偏差。生成的月度数据集不仅支持"双碳"目标的精细化分解,其方法学框架(如特征选择策略、混合建模思路)还可推广至全球其他地区的排放估算,为《巴黎协定》的履约监测提供新工具。未来随着县级能源调查数据的完善,该方法可进一步融合实测数据提升微观尺度精度。
生物通微信公众号
知名企业招聘

