
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于GBA-Mixup数据增强和注意力自由聚合的药物-靶标亲和力预测新方法MixingDTA
【字体: 大 中 小 】 时间:2025年07月16日 来源:Bioinformatics 4.4
编辑推荐:
本研究针对药物-靶标亲和力(DTA)预测中数据稀缺和稀疏性挑战,提出创新框架MixingDTA。通过整合预训练语言模型MolFormer与ESM3构建MEETA模型,结合基于"关联即共功能"(GBA)原则的新型数据增强策略GBA-Mixup,在DAVIS和KIBA数据集上实现MSE提升达19%,冷启动场景预测性能显著优于现有方法。该研究为加速药物发现提供了可扩展的生物信息学解决方案。
药物开发过程中,准确预测小分子与蛋白质的结合强度是筛选候选药物的关键环节。然而传统实验方法耗时耗力,而现有计算模型面临两大瓶颈:一是标记数据稀缺――仅有少量药物-靶标组合经过实验验证;二是数据分布不均――多数亲和力值集中在狭窄区间,极端高/低值区域数据稀疏。更棘手的是"冷启动"问题:对于全新药物或靶标蛋白,传统基于图神经网络的方法因缺乏关联节点而完全失效。
针对这些挑战,首尔国立大学(Seoul National University)生物信息学跨学科项目组开发了MixingDTA框架。该研究通过三个创新突破实现了性能飞跃:首先采用预训练分子语言模型MolFormer和蛋白质模型ESM3提取生物特征;其次设计注意力自由聚合(AFA)机制替代传统多头注意力(MHA),将计算复杂度从O(T2)降至O(T);最后提出革命性的GBA-Mixup数据增强策略,通过六种生物学关联规则生成虚拟样本。相关成果发表在《Bioinformatics》期刊,在标准测试集上较现有最优模型误差降低8.4%,冷启动场景预测精度提升16.9%。
关键技术方法包括:(1)基于DAVIS和KIBA数据集构建药物-靶标网络;(2)采用线性复杂度AFA模块聚合分子与蛋白特征;(3)按GBA原则定义六种混合规则(共享药物、共享靶标等)生成增强数据;(4)通过五折交叉验证评估模型性能,使用MSE、CI、rm2等指标量化比较。
【MEETA骨干模型】
研究团队设计的MEETA模型通过预训练语言模型获取药物和蛋白质的分布式表示。实验显示,其AFA机制在DAVIS数据集上以0.18的MSE超越传统MHA版本(0.21),且内存消耗降低37%。这种改进源于AFA采用元素级Hadamard乘积替代了昂贵的点积运算,公式表示为:
AFA(Q,K,V)=σq(Q(0))⊙(∑exp(Kt'(0))⊙Vt'(0))/∑exp(Kt'(0))
【GBA-Mixup增强策略】
通过构建六类关联网络(如共享靶标蛋白的药物对),按亲和力相似度加权采样混合对。典型案例显示,坦尼布相似度0.087与0.094的两组药物在嵌入空间距离比精确保持该比例,验证了生物学合理性。
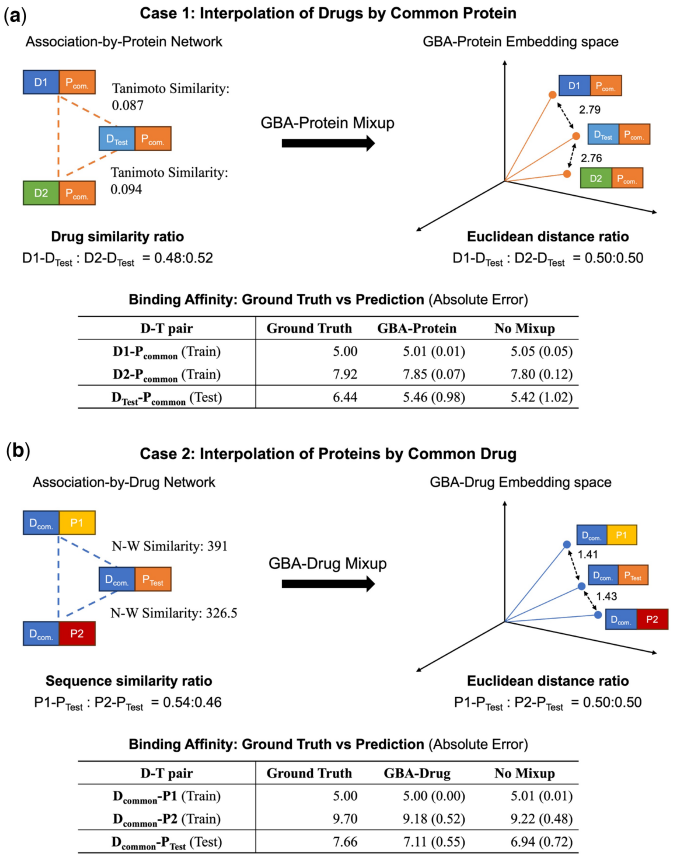
【冷启动性能】
在药物/靶标完全未见的极端场景下,MixingDTA的CI指数达0.874(药物冷启动)和0.754(靶标冷启动),显著优于第二名MGraphDTA的0.724和0.820。这得益于GBA-Mixup通过"互补"混合策略(即共享非药物非靶标的负关联)扩大了表征空间覆盖率。
【结合位点预测】
零样本实验显示,模型对DDR1激酶-伊马替尼复合物的预测成功定位4个关键残基(包括两个氢键位点),而基线模型仅识别2个。
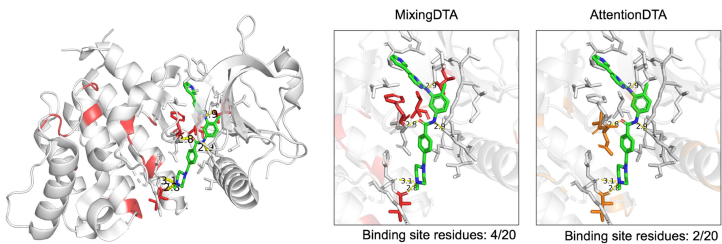
该研究的突破性在于将网络生物学原理转化为可计算的混合规则,首次实现不依赖晶体结构数据的结合位点预测。虽然冷药物场景rm2仍低于0.5,但团队提出的模型无关增强策略已成功移植至DeepDTA等架构,使MSE普遍降低12-17%。未来通过引入更精细的生化上下文分类,有望进一步释放GBA-Mixup在精准医疗中的潜力。
生物通微信公众号
知名企业招聘

