
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
稀疏交互建模实现生物银行规模研究中全基因组上位效应的快速检测
【字体: 大 中 小 】 时间:2025年07月30日 来源:AJHG 9.8
编辑推荐:
本研究针对生物银行规模数据中上位效应检测的计算瓶颈,开发了稀疏边际上位效应(SME)测试方法。该方法通过将上位效应搜索聚焦于与性状功能相关的基因组区域,显著提高了统计功效,并在UK Biobank的349,411个体中鉴定出与调控基因组元件相关的遗传互作。研究通过DNase I超敏感位点和GWAS汇总统计数据构建功能富集区域,使算法运行速度比现有方法快10-90倍,为大规模非加性遗传效应研究提供了新工具。
在复杂性状遗传解析领域,非加性遗传效应尤其是基因间互作(epistasis)的检测长期面临计算瓶颈。尽管全基因组关联研究(GWAS)已鉴定数千个与复杂性状相关的遗传位点,但上位效应在人类复杂性状中的作用仍存争议。传统互作检测方法受限于组合爆炸问题,而现有边际上位效应测试如MAPIT和FAME难以扩展到生物银行规模的数百万标记和数十万样本分析。
Brown大学和Microsoft Research的研究团队开发了稀疏边际上位效应(SME)测试,通过创新性地结合功能基因组数据与高效算法,实现了生物银行规模数据中上位效应的全基因组检测。该成果发表于《The American Journal of Human Genetics》,为解决非加性遗传效应研究的计算挑战提供了新方案。
研究采用三大关键技术:(1)基于DNase I超敏感位点(DHS)和GWAS汇总统计数据构建功能富集区域掩模;(2)开发混合效应模型方差组分估计的随机矩量法(MoM)算法;(3)应用Mailman算法和Hutchinson随机迹估计器加速矩阵运算。分析数据来自UK Biobank的349,411名欧洲裔个体,经严格质控保留543,813个SNP。
"计算效率"部分显示,SME在Intel Xeon Platinum 8268单核上完成全基因组分析仅需3.7天,较FAME和MAPIT分别提速10倍和90倍。
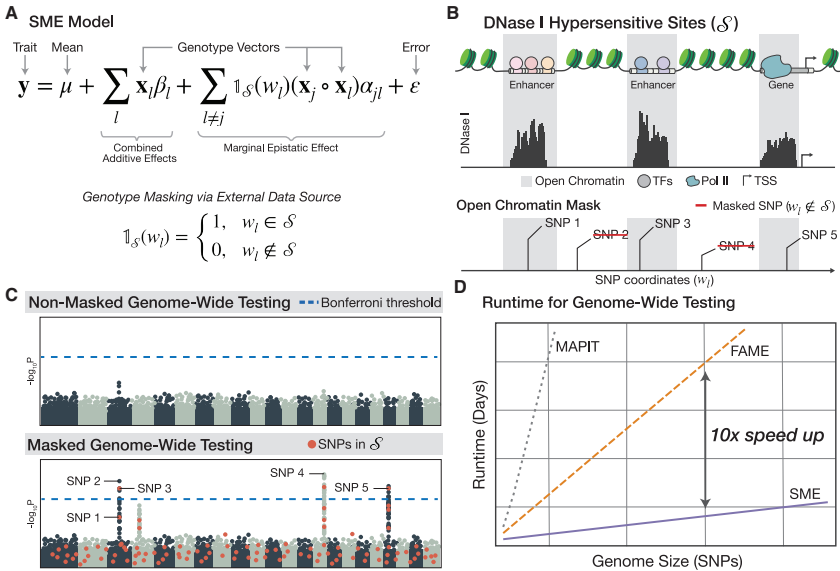
"统计校准"实验证实,在零模型下SME保持良好的一类错误控制(表1)。当使用均匀稀疏掩模时,300,000样本量下经验型I类错误率为0.0404(α=0.05),显著优于FAME的0.1208。而局部稀疏掩模虽保守但可通过添加随机SNP缓解偏差。
"检测功效"分析显示,99%掩模的SME在300,000样本中可检测单个SNP解释0.1%表型方差的互作(检出率85.1%),而FAME仅1%。

应用研究中,团队使用红细胞分化期DHS数据分析血液学性状。在平均红细胞血红蛋白量(MCH)中鉴定出7个显著上位SNP(如rs4711092,p=1.41×10-11),均位于SCGN和CARMIL1等已知红细胞相关基因(表2)。
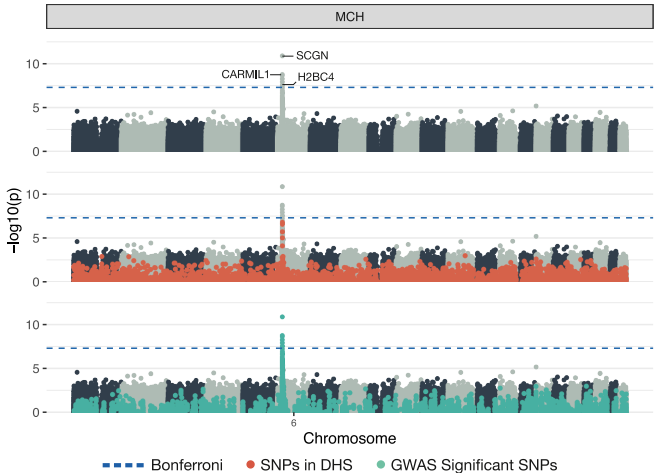
该研究通过创新算法与生物先验的融合,突破了上位效应检测的规模限制。SME的稀疏建模策略不仅适用于特定组织功能数据,也可扩展至GWAS汇总统计等通用信息源。研究证实红细胞性状中上位效应富集于转录调控区域,为理解复杂性状遗传架构提供了新视角。开源软件sme的发布将促进这一方法在遗传学研究中的广泛应用。未来工作可进一步优化掩模构建策略,并将框架扩展至病例对照性状分析。
生物通微信公众号
知名企业招聘

