
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于多阶段迁移学习和RoBERTa模型的假新闻检测与分类研究
【字体: 大 中 小 】 时间:2025年08月06日 来源:Scientific Reports 3.9
编辑推荐:
本研究针对社交媒体假新闻检测中标注数据有限、语言特征复杂等挑战,提出了一种融合Word2Vec嵌入和多阶段迁移学习的RoBERTa优化框架。通过系统比较不同嵌入技术,在Politifact和GossipCop数据集上实现97.03%和95.90%的准确率,较现有技术提升至少3.9%,为低资源场景下的虚假信息治理提供了可解释的解决方案。
在信息爆炸的社交媒体时代,假新闻如同数字病毒般以每秒数百万次的速度传播。研究表明,约57%的用户通过社交网络获取新闻,其中大量信息存在严重失真。这种"信息疫情"不仅扭曲公众认知,更可能引发政治动荡和社会撕裂。传统检测方法受限于标注数据稀缺、语义特征捕捉不足等问题,尤其在早期传播阶段难以有效拦截虚假信息。
沙特阿拉伯伊玛目穆罕默德・本・沙特伊斯兰大学计算机与信息科学学院的研究团队在《Scientific Reports》发表创新成果,通过多阶段迁移学习框架将RoBERTa模型的强大语义理解能力与Word2Vec的分布式表征相结合,构建出可解释、高精度的假新闻检测系统。该研究首次系统评估了不同嵌入技术(Word2Vec vs 独热编码)在低资源场景下的性能差异,并采用两阶段微调策略实现模型性能的阶梯式提升。
关键技术包括:1)基于POS(Part-of-Speech)标记的文本预处理;2)Word2Vec和独热编码的对比嵌入;3)RoBERTa的双阶段迁移学习(先领域适应再任务微调);4)动态层冻结技术。实验使用Politifact(500篇)和GossipCop(10,000篇)两个真实世界数据集,通过控制变量法验证各模块贡献。
【模型架构】
研究团队设计的"预处理-嵌入-迁移"三级架构如图1所示:

【嵌入技术对比】
如表2-3所示,Word2Vec使RoBERTa在Politifact上的准确率(97.03%)比独热编码(87.11%)提升9.92个百分点。特别在真实新闻识别中,精确度达98.57%,F1值97.87%。混淆矩阵(图5)显示仅2例真实新闻被误判:

【迁移学习优化】
两阶段微调策略(表10)使准确率较单阶段提升2.53%。动态层冻结实验(表9)表明:全层微调时模型性能最优,冻结底层6层会导致GossipCop数据集F1值下降3.26%。训练曲线(图4)显示损失函数快速收敛:
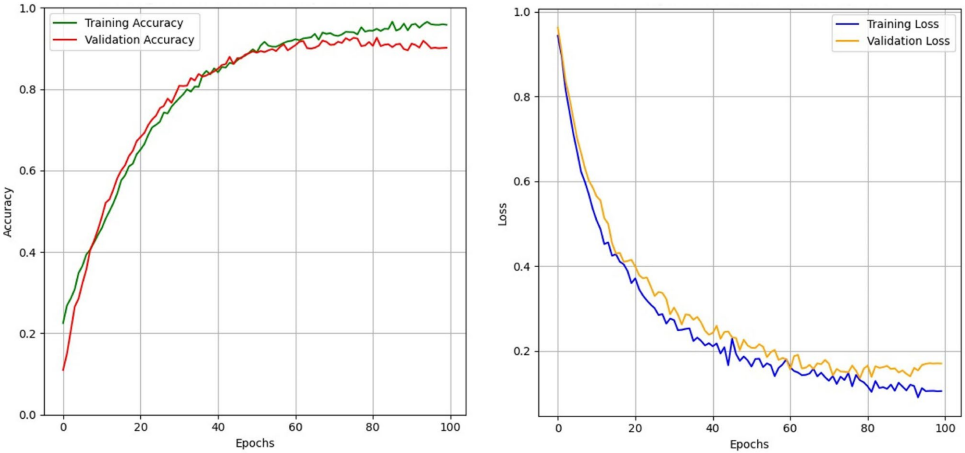
这项研究突破了小样本条件下假新闻检测的精度瓶颈,其创新性体现在三方面:首先,通过嵌入技术对比揭示了语义特征对模型性能的决定性影响;其次,多阶段迁移学习策略实现了预训练知识向特定任务的高效转化;最后,提出的框架在保持RoBERTa原有参数效率的同时,将政治类假新闻检测推至97%的准确度。未来可扩展至多模态数据融合,为构建"社交防火墙"提供核心技术支撑。
生物通微信公众号
知名企业招聘

