
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于文本提示的大词汇量3D医学图像分割模型SAT:构建多模态知识树与通用分割新范式
《npj Digital Medicine》:Large-vocabulary segmentation for medical images with text prompts
【字体: 大 中 小 】 时间:2025年09月04日 来源:npj Digital Medicine 15.1
编辑推荐:
本研究针对医学图像分割领域存在的模型专业化局限、交互式分割效率低下及3D上下文缺失等核心问题,开发了首个基于文本提示的3D医学图像通用分割模型SAT(Segment Anything with Text)。研究团队构建了包含6502个解剖术语的多模态知识树,整合72个公开数据集形成22K扫描图像的SAT-DS训练集,通过对比学习将医学知识注入文本编码器。SAT-Pro模型(4.47亿参数)在497类解剖结构分割中达到与72个nnU-Net专家模型(合计22亿参数)相当的性能,平均Dice相似系数(DSC)较交互式MedSAM提升7.1%,在跨中心验证中展现优异泛化能力。该研究为临床提供了可无缝对接大语言模型的通用分割工具,推动医学人工智能向通用化发展。
医学图像分割是疾病诊断和治疗规划的关键技术,但传统方法面临三大困境:专家模型(如nnU-Net)需为每个器官单独训练,2.2亿参数的72个模型才能覆盖497类解剖结构;交互式模型(如MedSAM)依赖人工标注空间提示,单次3D扫描需10-60次交互;而自然图像预训练的SAM模型难以捕捉3D医学图像的上下文信息。这些局限性严重制约了临床应用的效率和普适性。
为解决这些问题,Ziheng Zhao等人在《npj Digital Medicine》发表研究,提出SAT(Segment Anything with Text)框架。该研究通过三大创新突破技术瓶颈:首先构建覆盖6502个术语的解剖知识树,整合72个数据集形成标准化SAT-DS训练库;其次设计知识注入机制,通过对比学习将文本定义与3D图谱特征对齐;最终开发基于Transformer的查询解码器,实现文本提示驱动的端到端3D分割。
关键技术方法
研究整合22,186例CT/MRI/PET扫描(来自72个公开数据集),通过轴向重采样(1×1×3 mm3)和模态特异性强度归一化处理数据。采用知识增强的PubMed-BERT文本编码器,在6502个概念-定义对上预训练后,与3D U-Net视觉编码器通过跨模态注意力机制耦合。训练110M参数的SAT-Nano和447M参数的SAT-Pro两个模型,采用Dice+交叉熵联合损失函数。
主要研究结果
性能对比专家模型
SAT-Pro在头颈、胸部和四肢等区域DSC超越nnU-Net,整体性能与72个专家模型相当(p>0.09),而参数量仅后者20%。
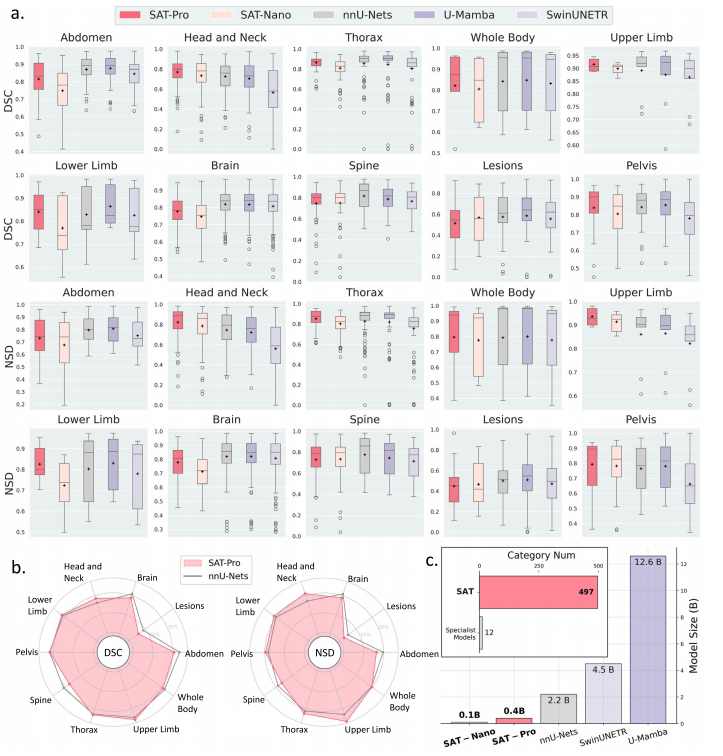
超越交互式模型
在心肌等不规则结构分割中,SAT-Pro较MedSAM(Tight)平均DSC提升7.1%,且对空间提示误差具有鲁棒性。

知识注入有效性
采用知识增强文本编码器的模型在长尾类别(占比3.25%的150类)DSC提升显著,概念检索Recall@1达99.18%。
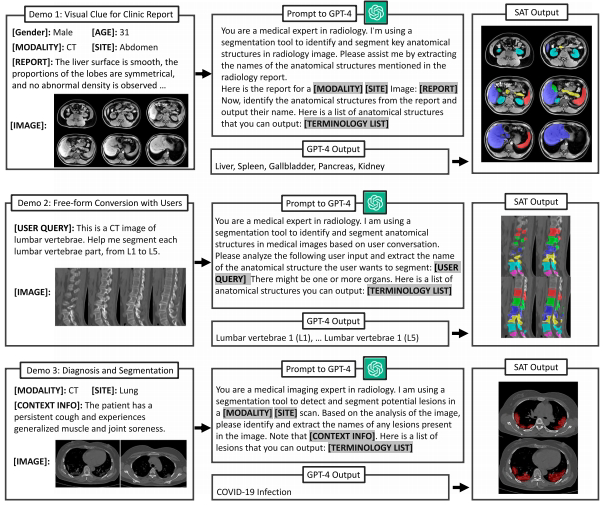
临床集成应用
与GPT-4结合实现三大场景:临床报告目标自动解析、自然语言交互分割、基于EHR的病灶定位。
研究意义
该工作首次证明医学分割领域存在类似大语言模型的缩放定律――参数量增加带来性能提升。SAT-Pro的通用性使其可替代数十个专家模型,降低临床部署成本。知识注入机制有效缓解长尾分布问题,为罕见解剖结构分割提供新思路。作为语言模型与医学图像的桥梁,SAT为构建通用医疗人工智能奠定了基础。未来可通过扩展模型规模、开发开放词汇分割等方法进一步突破性能边界。
生物通微信公众号

