
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
基于自然语言处理技术的儿科长新冠症状识别研究:RECOVER项目多中心分析
【字体: 大 中 小 】 时间:2025年09月05日 来源:JAMIA Open 3.4
编辑推荐:
本研究针对儿童长新冠(Long COVID)症状识别难题,开发了结合规则引擎与深度学习模型的自然语言处理(NLP)管道,通过分析12家医疗机构48,287份门诊记录,成功从非结构化电子健康档案(EHR)中提取21种症状和4类功能影响特征。研究证实NLP方法能显著补充结构化数据,揭示长新冠患儿更易出现疼痛(OR=2.3)和消化问题(OR=2.1)等特征,为儿科长新冠的精准识别提供了新范式。
儿童长新冠的"文字侦探":如何从海量病历中捕捉隐藏信号
当全球还在应对COVID-19大流行的急性期时,一个更隐蔽的威胁――长新冠(Long COVID)逐渐浮出水面。这种被美国国家科学院定义为"SARS-CoV-2感染后持续≥3个月的多系统慢性病症",在儿童群体中尤其难以捉摸。没有特异性生物标志物,症状复杂多变,加上儿科患者表达能力的局限,使得传统依赖诊断编码的结构化电子健康档案(EHR)分析往往力不从心。临床笔记中埋藏着大量未被编码的宝贵信息,但如何系统性地挖掘这些非结构化文本?这成为H. Timothy Bunnell博士团队在《JAMIA Open》发表的重要研究要解决的核心问题。
研究团队创新性地构建了混合方法NLP管道,从RECOVER项目12家医疗机构的48,287份门诊记录中提取信息。关键技术包括:1)使用Spark-NLP开源框架结合定制化正则表达式规则集;2)开发包含词向量(word2vec)模型的复合断言系统;3)建立25个长新冠相关临床概念的专业词典;4)采用多中心匹配队列设计(10,618名患儿,1:1匹配长新冠与急性COVID组)。
方法学突破:从"识别"到"断言"的双重验证
研究最显著的创新在于解决了NLP应用中的核心挑战――准确区分症状的"存在"与"否定提及"。通过让8位儿科专家标注4,586个实体,团队开发出融合规则引擎、词向量和双向LSTM的三重断言模型,使F1值从基础模型的0.68提升至0.90。这种复合方法特别擅长处理临床常见的模糊表达,如"否认抑郁但存在注意力问题"这类复杂语境。
数据源的互补价值:结构化与非结构化的"双人舞"
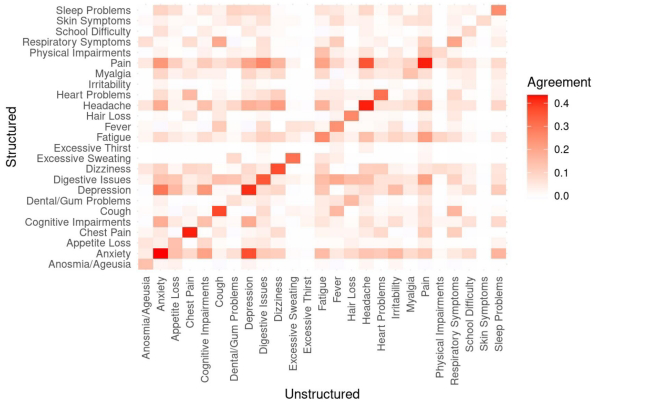
图4热图揭示了结构化编码与文本提取特征间的微妙关系:虽然焦虑(r=0.43)和头痛(r=0.39)等特征在两种数据源中表现适度相关,但更多特征如易怒(r≈0)则几乎毫无关联。更引人注目的是图5的"三色分布":在疼痛症状识别中,仅通过NLP发现的病例数(1,892)远超仅通过编码识别的数量(241),凸显文本挖掘对症状捕捉的敏感性优势。
跨机构一致性:方言差异下的"通用语"
尽管来自不同医疗系统,12家机构在症状提及频率上展现出显著一致性(66项相关性中64项达显著性)。图6B中那条"特立独行"的红色曲线(站点A)恰好证明了方法的鲁棒性――即使存在区域性表达差异(如该站点消化问题提及率异常高),核心症状谱仍保持稳定模式。
临床与实践意义
这项研究为儿科长新冠研究树立了新标准:首先,证实了EHR文本挖掘可补充高达40%的结构化数据遗漏病例;其次,开发的NLP管道具有跨机构适用性,其开源组件(https://github.com/RECOVER-Coordinating-Center)可直接支持后续研究;最重要的是,研究揭示儿童长新冠的独特表现谱――与成人不同,疼痛(OR=2.31)和消化症状(OR=2.14)而非疲劳成为最显著特征,这为儿科专科诊断提供了重要参考。
局限性与未来方向正如作者指出,当前研究聚焦症状流行率而非发生率,可能包含基础疾病干扰。团队计划在后续工作中引入未感染对照组,并探索大语言模型(LLM)在时序症状追踪中的应用。这项来自RECOVER计划的开创性工作,不仅为长新冠研究提供了方法论范例,更深刻展示了多模态医疗数据分析在慢性病研究中的变革潜力。
生物通微信公众号
知名企业招聘

